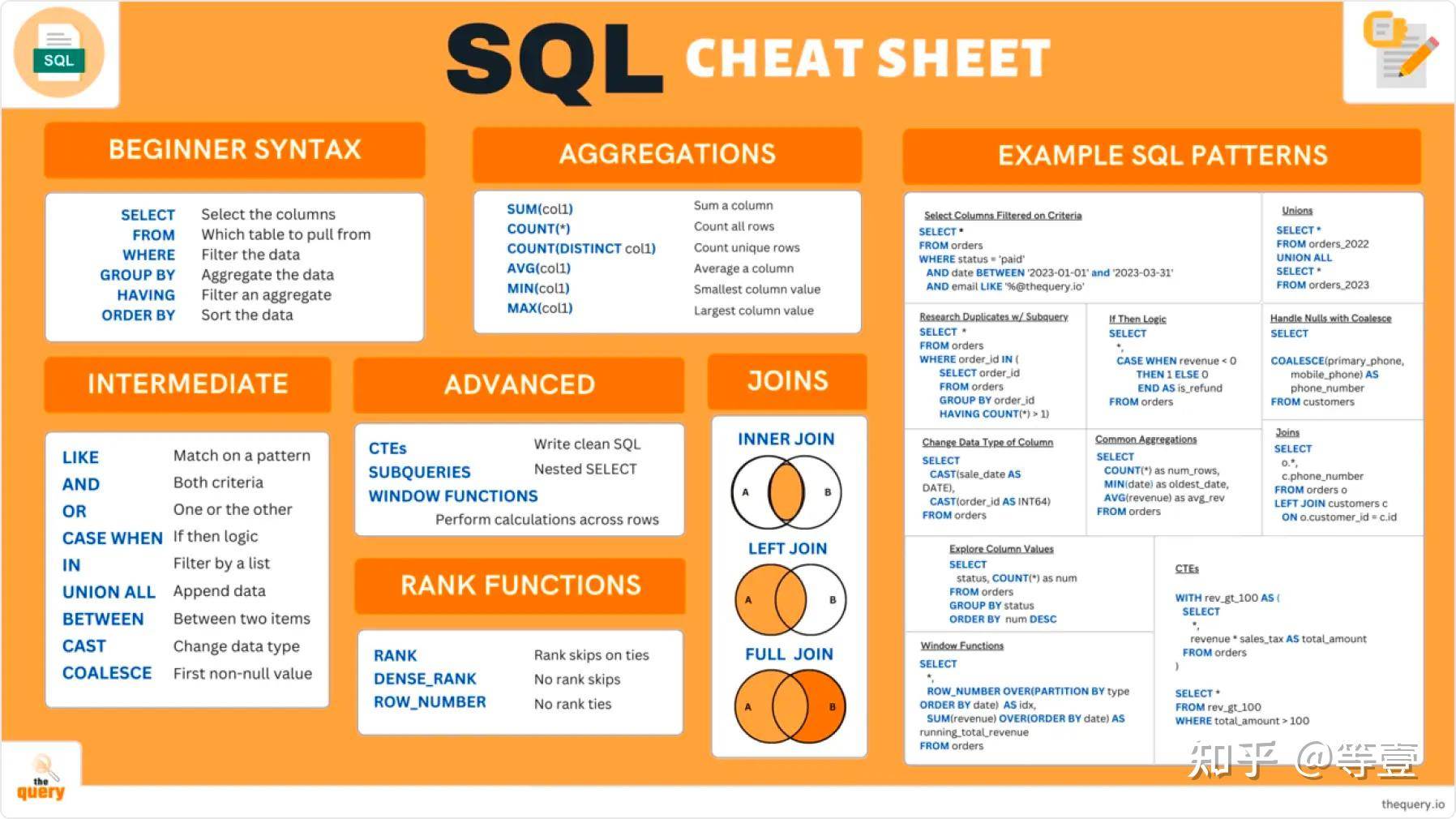
面试官灵魂拷问:为什么 SQL 语句不要过多的 join?
有一个回答说得很对。。。。 “面试官,你们没用过好用的数据库。你也不懂数据库。”
这不让那不让,动不动就大数据。。。动不动就照搬阿里巴巴的规范。。。
面试过几个互联网云原生原教旨主义者,张嘴闭嘴大数据,不管3721一律分库分表分布式。我问,你们表最大多少行?答曰500w。500w算个毛线大数据啊,连HDD的MySQL的性能蜕化点都够不着。
又譬如互联网人重视“效率”,说视图(view)每次查询效率很低,我问他怎么解决,他说“我创建个表,定期把结果数据更新进去“。这不就是物化视图(material view)么?是否可以用material view只JOIN增量的部分,然后再Merge进去总量的结果表呢?明明一句查询可以搞定的东西,非要上一套大数据引擎,况且,在绝大多数情况下,数据库的运算效率比你自己写的都要高。
只要有JOIN的必要在那里,不在数据库里头做那就在应用里头做。在应用层面做,你要先付出IO的成本,如果真的因为“数据量大”而不去JOIN,那这个IO成本一定不会低。应用程序所使用的优化手段(细化JOIN的范围、只处理增量的部分等),绝大部分情况下对数据库也适用。把这些逻辑放在数据库层面做,可以直接节省下IO成本,数据量越大,这个效率提升就越大。
所谓的JOIN慢并不是JOIN本身慢,而是这帮人每一次都按全量数据去处理。。但他们自己写应用逻辑的时候,又按增量的方式去更新(例如ETL)。。你用增量去和全量比,有点不公平。。如果是借着JOIN的名义做着各种各样复杂业务处理的事情,这就属于你的问题了,别甩锅给数据库。
互联网人的知识体系还停留在HDD年代,完全不顾现代NVME SSD的发展历程。对于绝大多数公司(剔除阿里巴巴、腾讯等某几家头部),从成立到倒闭积累的数据量都不会超过40T。与其搞那么多分布式,用几倍的运维管理成本来换取一丁点的读写性能提升,还不如直接上NVME SSD阵列,先把单机容量和IO性能顶上去,方案更简单、更直接,管理成本更低。哪怕是最低级的消费级SSD组成的阵列,立刻获得8~20倍以上的读写性能提升。
单表500G,全库20T,现代数据库在NVME SSD加持下轻轻松松不费吹灰之力。
说这些只想表达,现代单体数据库没你们想的那么弱,吹上天的伪分布式数据库也没你们想的那么万能,绝大多数场景下你们的数据量也远远远远远没到达能把分布式OLAP系的Citus用出性价比的程度。你们基础不牢固,不分场景滥用、误用导致的锅,别甩给数据库。对于各位互联网云原生高并发高性能大数据超融合原教主义者,奉劝一句:耗子尾汁。
========== 追更1 ==========
观众有点多,感谢捧场……既然大家这么热情我就多写一点……
既然这样那就再讲讲 A字头国产大厂O字头的王牌产品,主打特点是“分布式“。我理解的“真分布式”对外应该是一个超级大的单体,类比于超融合架构,运维只管堆硬盘堆机器堆内存就完事。至于什么分区表、库在哪个节点,这些概念都应该统统不存在,毕竟你原生分布式了嘛。
但在实测过程中,单表写入到5kw时性能急剧退化到几乎无法插入。这个5kw,很有代表性,对MySQL Benchmark很熟悉的朋友应该意识到了。按常规做法直接走分区表,但想着主打“分布式”的卖点,是否有更简单、更直接的方法?秉承对新技术的敬畏之心,咨询了技术售后,答复是建分区表提高写入性能,做读写分离提高读取性能。。。。。
大失所望。。。就这????吹了大半天的“分布式”就这水平???不是说这方案本身不行,而是你那么高举高打,吹得那么牛逼,到头来给我一个连我这种非专业DBA都能想到的方案,就有点严重不及预期。。。。打个不恰当的比方,当你说分布式存储的时候,我预期是ZFS,最低最低的预期是RAID5,但你拿出来一个RAID1。。。
说你是嘛,也好像可以,但总觉得不是那么对味。用这样的分布式方案去和CitusData和TiDB去比性能,就有点不是那么够意思了。如果就这的话,哪怕是免费的MySQL、PG,用同样的方案就能解决,与这王牌产品宣称的特点没有显著差异。我不认为“读写分离+主从同步”是“真分布式”。
后续看了这王牌产品的官方文档,我更加认定,与其说是“分布式数据库”,更像是“数据库运维及配置平台”,强调的是“一写多读“场景下的弹性扩”读“的便利化和自动化。配合其自家的云平台,更好地做资源的弹性分配。以前需要DBA左搞又搞的,现在只需要点一下扩展到多少个只读节点,峰值过去了又可以弹性收缩回来,把N个读的给销毁掉。在接入层统一做路由和调度,实现底层实例的增减变动对应用层透明。
虽说也是一种有效的改进,但距离我心中认为的“原生分布式”还是有很大距离。相对之下,基于PG Extension机制的CitusData,我认为我更符合我对“原生分布式数据库”的实现。CitusData大家听的少,强烈建议有兴趣的同学去了解了解,非常有品味的方案。
========== 追更2 ==========
评论区提到了TiDB,TiDB和CitusData走彻头彻尾的分布式方案,核心包括分布式存储+分布式事务。一个走MySQL路线,一个走PG路线。
这个彻头彻尾的分布式路线呢,也是一种取舍,好处和坏处都会比较明显。好处呢,只管加机器,剩下的DB调度引擎自动帮你搞定,应用层完全透明;坏处呢,由于分布式存储和分布式事务的引入,一定会带来跨机器的IO,所以写入速度一定会比单体数据库要慢。读取和查询速度,在数据量特别特别大的时候,会比单体数据库有显著优势。
华为高斯、达梦等,走的是Oracle exadata的路线,说白了就是强单体,通过堆SSD、堆HDD、堆内存、堆CPU、堆存储机柜,先把单体性能顶上去,里头的优化略有差别但总体路线差别不大。
某王牌产品这种路线,属于在他自身业务下的一种非常特殊的形态,即平时能提供单体数据库的性能,在特殊时候可以迅速扩充到“多读友好“的模式。如果不是直接上云,其实一般公司玩不转。因为你的机器本身没有那么多弹性,你的需求也没那么多弹性。本质上我认为也谈不上“分布式”,只能说沾了点边。
三者对比下来,强单体优先,等到单体无论怎么优化都无法支撑了,再切换到彻头彻尾的分布式,是更合理、更务实的选择。
一上来就分布式,纯粹是给自己找堵。
========== 追更3 ==========
大家有兴趣的,可以去了解一下SQL Server的AlwaysOn,Oracle的RAC,PG的Shared Storage Failover的底层机制,这都是在“强单体”路线下迅速扩展读取能力的极度高效的机制。AlwaysOn走存储系统块同步机制,RAC和Shared Storage Failover走的是共享存储的机制,由存储系统提供稳定性保障。这里着重要强调一下RAC和Shared Storage Failover,这两种方案都是“无复制”方案。所以从性能上,一定会比主从同步更快。
了解完了再来对比某王牌产品的机制,会更有感觉。不是说它不好,而是说它对绝大多数场景下(数据量在160T以下、没有弹性的需求),都比不过强单体路线,无论是成本还是性能。
对于绝大多数场景,强单体 + 过得去的主从同步,基本能用到倒闭。